Here’s how most people build an eval. They open a file, write an LLM judge prompt that says something like “rate this response from 1 to 10 on helpfulness”, run it over a few hundred traces, get a pile of numbers back, and then have absolutely no idea whether those numbers mean anything.
I get it. It feels like progress. You’ve got a dashboard, you’ve got a metric trending, you can put it on a slide. But you’ve skipped the part that makes an eval worth running, which is knowing it agrees with a human. A number you can’t trust is worse than no number, because at least no number doesn’t lull you into thinking everything’s fine.
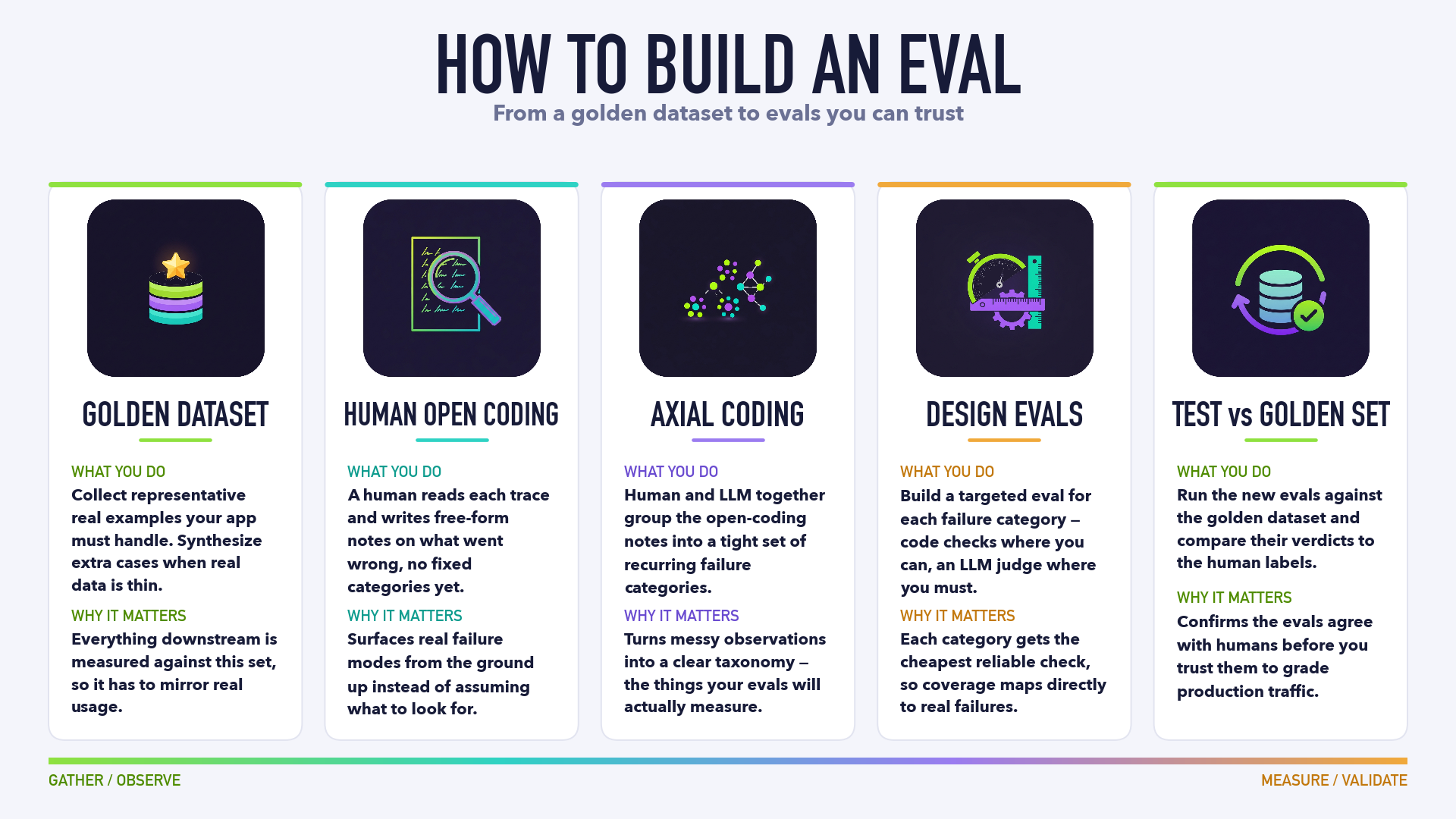
So here’s the longer way round. It’s five steps, and it borrows a trick from qualitative researchers - the people who code interview transcripts for a living and have been doing the “turn messy human judgement into something measurable” thing for decades.
Want it to hand? Download the infographic as a PDF.
The whole flow goes left to right, from gather and observe to measure and validate. The first half is about understanding what actually goes wrong. The second half is about building checks for it and proving they work. Skip the first half and you’re just guessing in a more expensive way.
Step 1: Gather a golden dataset
You can’t measure anything without a set of examples to measure against. So the first job is to collect a representative set of real interactions your app has to handle - the dull ones, the weird ones, the ones that fall over.
The word that matters here is representative. Everything downstream gets measured against this set, so if it doesn’t look like real usage, your evals are tuned for a world that doesn’t exist. Pull from production traffic if you’ve got it.
If you don’t have enough real data yet - and early on, you won’t - synthesise some. Generate examples that look like the traffic you expect. It’s not as good as the real thing, but a synthetic golden set you’ve thought about beats no golden set at all. Just be honest with yourself about which bits are made up.
Step 2: Human open coding
Now the unglamorous bit. A human - probably you - sits down and reads each example in the golden set, and writes free-form notes on what went wrong. Not against a checklist. Not “score this 3 out of 5”. Just plain notes: “made up a refund policy”, “ignored half the question”, “weirdly passive-aggressive tone”.
This is called open coding, and the whole point is that you have no fixed categories yet. You’re not confirming a theory about what your app gets wrong. You’re letting the failure modes show up on their own.
This matters more than it sounds. If you start with a list of things to check, you’ll only ever find the things on your list. Open coding surfaces the failures from the ground up - including the ones you’d never have thought to look for, which are usually the ones that bite.
Step 3: Axial coding
Open coding leaves you with a big messy pile of notes. Step three is turning that pile into a tight set of categories. This is axial coding, and it’s where you let an LLM earn its keep.
You and the model go through the notes together and group them into recurring failure categories. Forty scattered observations collapse into something like five real buckets: hallucinated policy, incomplete answer, tone problems, ignored context, broke format. The LLM is genuinely good at this - spotting that “made up a refund policy” and “invented a returns window” are the same underlying failure - and you’re there to sanity-check that the buckets actually make sense.
What you get out of this is a taxonomy. And that taxonomy is the thing your evals will measure. You’ve gone from “I think our bot is a bit off sometimes” to “here are the five specific ways it fails”, which is a much better place to be standing.
While you’re here, tag each example in the golden set with the categories it actually shows - including the ones that are simply fine. That labelled set is your ground truth, and it’s what you’ll check your evals against in a minute.
Step 4: Design the evals
Now, and only now, do you build evals. One per failure category. You know exactly what you’re checking for, because steps two and three told you.
For each category, pick the cheapest method that’ll do the job. Broke format is a code check - free, fast, deterministic. Passive-aggressive tone needs an LLM judge, because no regex is going to catch attitude. Some categories want a bit of both. I went through the whole spectrum of how to run these - plain code checks, LLM judges, code-and-LLM hybrids, and full agentic harnesses - in a separate post on the four ways to run an eval, so I won’t repeat it here.
The point is that by this stage, designing the eval is the easy part. You’re not guessing what to measure. You’re building a known check for a known failure.
Step 5: Test against the golden set
This is the step everyone skips, and it’s the one that makes the whole thing trustworthy.
You’ve got your golden set. You’ve got human labels on it from steps two and three - you know what actually went wrong in each example. So run your shiny new evals back over that same golden set and check whether they agree with the human verdicts.
If your tone judge flags the same responses you flagged, brilliant - that’s real evidence it’ll hold up on traffic it’s never seen. If it disagrees, you’ve caught it now, on a controlled set, instead of six weeks into production when it’s been quietly grading the wrong thing the whole time. Tweak the eval, run it again, repeat until it lines up with the humans.
That’s the bit that turns a number into a number you believe. Your eval has been checked against ground truth before it ever touches live data.
Why bother with all this
Because the alternative is a metric that looks like signal and is actually noise, and those are dangerous - they’re confidently wrong, and they’re on a dashboard, so everyone trusts them.
The open-coding-then-axial-coding move is the bit worth stealing even if you ignore everything else here. Look before you measure. Let the failures tell you what the categories are, instead of deciding the categories first and forcing reality to fit. Researchers have been doing it for decades because it works, and it carries over nicely from a stack of interview transcripts to a pile of agent traces.
Build the golden set, read it properly, find the real failure modes, build a check for each one, and prove those checks agree with you. Then you’ve got an eval you can actually trust - and once you trust it, running it is the easy part.