There’s a version of building an AI app that goes like this. You build the thing, you get it mostly working, and then someone says “should we evaluate it?” and you bolt some evals on at the end like a spoiler on a hatchback. It runs, the numbers look fine, you ship.
That works about as well as writing all your tests the night before launch. Evals aren’t a stage you do once at the end. They’re something that runs the whole way through, doing a different job at each step. Get that idea straight and the rest of this falls into place.
Want it to hand? Download the infographic as a PDF.
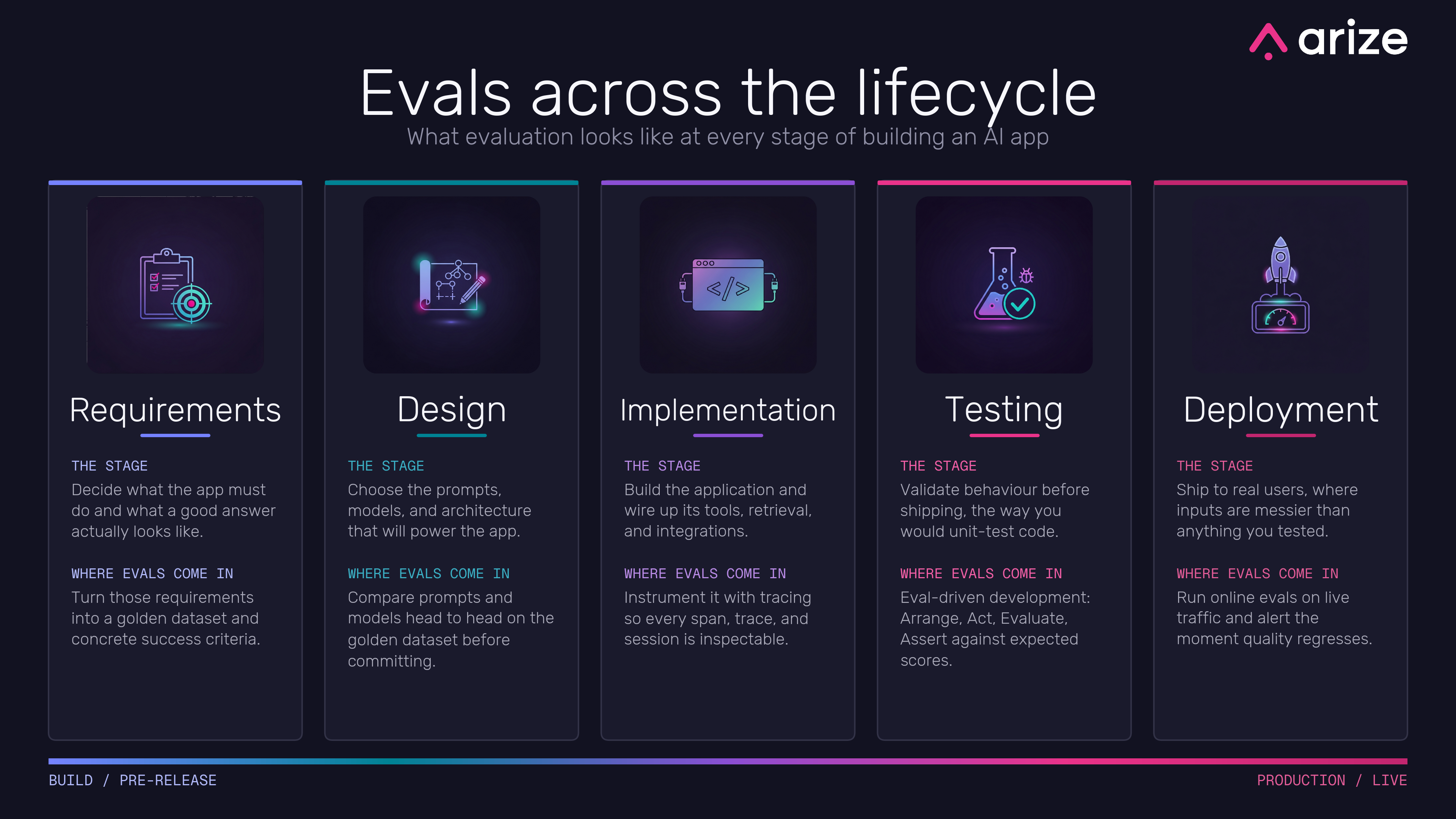
The whole thing runs left to right, from build and pre-release over on the left to production and live on the right. Same lifecycle you already know from normal software. The difference is that an AI app is non-deterministic, so “does it work” isn’t a yes or no you can answer once. You have to keep asking, at every stage, and an eval is how you ask.
Requirements
Before you write a line of code, you have to decide what the app is actually for and what a good answer even looks like. This sounds obvious and almost everyone skips it.
The trap with AI is that “good” feels self-evident until you try to pin it down. A good support reply is… helpful? Polite? Correct? Grounded in the actual docs? Those are four different things, and an answer can nail one and fail the others. So this is where you turn fuzzy intentions into concrete success criteria, and start gathering the examples that show what good looks like. That collection becomes your golden dataset, which everything downstream gets measured against. I wrote a whole post on building an eval you can trust, because it’s the foundation the rest sits on.
Design
Now you choose how to build it. Which prompts, which model, what architecture. And here’s where most people go on vibes - they try a prompt, it looks good in the playground, they ship it.
The better move is to make those decisions on evidence. You’ve got a golden dataset from the last step, so use it. Run two candidate prompts against it and see which actually scores higher. Compare a cheaper model against an expensive one on the cases that matter to you, not on a leaderboard built from someone else’s data. Design becomes a series of small head-to-head bake-offs instead of a series of hunches, and you end up committing to choices you can defend.
Implementation
You build the app. You wire up the tools, the retrieval, the integrations, all the moving parts. Nothing surprising here, except for one thing you have to do that you might not be used to: instrument it.
Tracing isn’t optional for an AI app. When something goes wrong - and it will - you need to see what the app did, step by step, to figure out why. That means every span, every trace, every session is captured and inspectable. If you don’t have that, debugging an AI app is just guessing with extra steps. (Span, trace and session are the three levels you’ll be looking at, and they’re worth understanding properly - here’s a post on exactly that.) Get the instrumentation in now, while you’re building, not after you’ve shipped and you’re trying to bolt it on under pressure.
Testing
Now you validate before you ship, the same way you’d unit-test normal code. The twist is that you can’t assert on an exact output, because the output changes every run. So the shape of the test changes too.
Normal testing goes arrange, act, assert. You set things up, you run the code, you check the result is exactly what you expected. Eval-driven development adds a step: arrange, act, evaluate, assert. You set things up, you run the app, you run an eval on whatever came back, and then you assert on the eval’s score. You’re not checking the output equals a fixed string. You’re checking the output scores above the bar you set in the requirements. Same testing instinct, adjusted for a world where the answer is never byte-for-byte the same twice.
Deployment
You ship, and your app meets real users. Real users are messier than anything you tested with. They ask things you never imagined, in ways you never anticipated, and the neat distribution of inputs you tuned everything against goes out the window.
So the evals don’t stop at the door. They follow the app into production. You run online evals on live traffic, scoring real responses as they go out, and you alert the moment quality drops. This is the part that turns “it worked when we tested it” into “it’s still working right now”, which is the only version that actually matters once people depend on it.
The thread that runs through it
Notice what carries the whole way along. The golden dataset and the success criteria you defined at the very start are the same yardstick you use to compare designs, to test before shipping, and to judge live traffic. Define “good” once, properly, and it pays off at every stage after.
That’s the real point. Evals aren’t a gate at the end that says yes or no. They’re a feedback loop you run continuously, from the first requirement to live production traffic, and the job they do shifts as you move along. Bolt them on at the end and you’ll catch the odd bug. Thread them through from the start and you actually know, at every step, whether the thing works - which, for something as slippery as an AI app, is about the most valuable thing you can know.