When people decide to use an LLM as a judge, the prompt they reach for first is almost always some flavour of “rate this response from 1 to 10 on quality”. Then they’re surprised when the scores are all over the place and don’t agree with anything a human would say.
The reason is simple. That isn’t a prompt, it’s a coin toss with extra steps. You haven’t told the model who it’s meant to be, what “quality” means, what the numbers stand for, or what a good answer looks like. It’s filling in all of that itself, differently, every time you run it. A judge is only as good as the prompt behind it, and a good prompt has four parts.
Want it to hand? Download the infographic as a PDF.
The four parts run left to right from who is judging to how they score. Each one removes a little more of the model’s freedom to guess, and that’s the whole game. A reliable judge is one you’ve left as little room as possible to improvise.
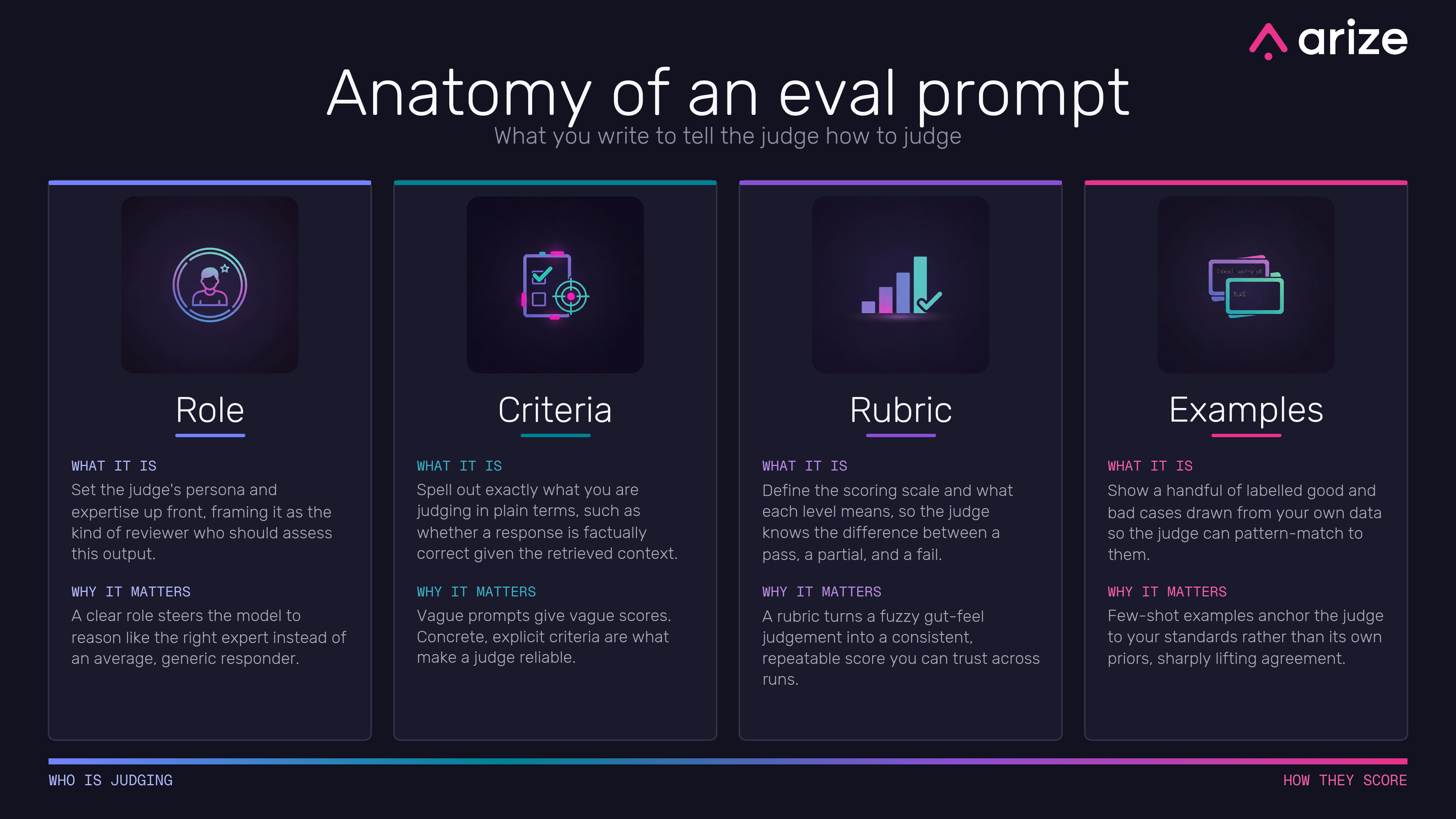
Role
Start by telling the model who it is. Not “you are a helpful assistant”, but the specific kind of expert who’d be the right person to assess this particular output. You are an experienced support-quality reviewer. You are a senior engineer reviewing a code explanation for accuracy.
This feels like window dressing and it isn’t. A model with no role defaults to being a generic, agreeable, average responder, and average responders are soft markers - they want to give everyone a 7. Naming the role steers it to reason like the right expert, with the standards that expert would actually hold. You’re picking who shows up to do the judging, and it changes the answers you get.
Criteria
Now spell out exactly what you’re judging, in plain language. Not “quality”. The actual thing. Is this response factually correct given the retrieved context? Does it answer every part of the question the user asked? Is the tone appropriate for a frustrated customer?
This is the part that does the most work, and it’s the part people most often wave at. Vague criteria give you vague scores, every time. If you can’t say precisely what you’re checking for, the model certainly can’t, so it’ll invent its own definition and grade against that. The more concrete and explicit you are about what good means, the more reliable the judge becomes. This is the same “decide what good looks like” discipline that the whole build-an-eval process is built around, applied to a single prompt.
Rubric
Criteria tell the judge what to look at. The rubric tells it how to score what it sees. Define the scale and, crucially, what each level on it actually means. What’s a pass? What’s a partial? What’s an outright fail, and what specifically tips a response from one into the next?
Without this, a 1-to-10 score is meaningless - the model’s 6 today is its 8 tomorrow, because nothing anchors them. A rubric with described levels turns a fuzzy gut feeling into something repeatable. Two runs over the same response should land on the same score, and two different responses with the same problem should score the same way. That consistency is the entire reason you’re scoring things in the first place, and the rubric is what buys it.
Examples
Last, show the judge a handful of real cases with the labels you’d give them. A couple of clear passes, a couple of clear fails, drawn from your own data - the actual responses your actual app produced, judged the way you’d judge them.
These few-shot examples are the strongest lever of the four. A model left to its own devices judges against its own priors, which are some average of the entire internet. Show it three good and three bad examples from your domain and it stops guessing and starts pattern-matching to your standard instead. This is also exactly where a proper train/dev/test split earns its keep: the examples come from your training slice, so you’re never showing the judge a case you later use to score it.
The pattern underneath
Look at the four parts together and there’s one idea running through all of them: every part you add takes away a little of the model’s freedom to make things up. Role decides who’s judging. Criteria decide what they’re judging. The rubric decides how they score it. Examples show them exactly what you mean. Each one closes off another way for the judge to drift.
That’s the real anatomy of a good eval prompt. Not “rate this 1 to 10”, but a tight brief that leaves a clear, specific, expert reviewer almost nowhere to improvise. Write that, and the scores start agreeing with you - which is the only thing that makes a judge worth running at all. The prompt is half the picture, though. The other half is what your eval platform does with it, which is a post of its own.